The strange thing about a very fast model is that it makes the old interface feel theatrical.
The streaming cursor. The slow paragraph forming line by line. The little pause where you convince yourself the model is thinking. The agent timeline that turns a small request into a job you are meant to check later.
Some of that is real work. A lot of it is latency dressed up as product design.
This is why Cerebras has been sitting in my head. The obvious story is that the company filed its S-1 for a proposed IPO on 17 April 2026, with a planned Nasdaq ticker of CBRS. That makes it a market story.
I think the more useful story is stranger than that.
At close to 1,000 output tokens per second, the model response stops feeling like a thing you wait for. It starts feeling like something you can move through.
That changes the unit of work.
The wait was shaping the software
Most AI products still carry the assumptions of slow inference.
You ask. You wait. You watch the output arrive. You decide whether to retry. If the task has several steps, the product usually turns it into a background agent run: queue it, stream progress, show a timeline, tell the user to come back later.
That design made sense because waiting changes behaviour. If a model takes 20, 40, or 90 seconds to work through a task, the human will usually leave the thought. They open another tab. They start another agent. They half-supervise three things and properly supervise none of them.
Then, later, they return to a result and try to remember what they were asking for in the first place.
Fast inference attacks that problem from a different direction. It does not make the model automatically better. It makes the loop shorter enough that the human can stay inside it.
That is the part I care about.
Fast inference is not interesting because it prints text quickly. It is interesting because it lets more supervised attempts happen before attention breaks.
Scaling thinking is smaller than it sounds
I keep coming back to the phrase "scaling human thinking", but I do not mean it in a grand way.
I mean something quite ordinary.
One person can run more drafts, checks, critics, tool calls, variants, and repairs while they still remember what they were trying to do.
That is enough to change the work.
For a coding task, the old loop might be:
- Ask for a patch.
- Wait.
- Read the patch.
- Ask for a review.
- Wait again.
- Ask for a fix.
- Lose patience or switch tabs.
The faster loop can feel more like:
- Draft it.
- Criticise it.
- Repair the weak bit.
- Check the risky assumption.
- Show me what still needs human judgement.
Same human. Same task. More thinking passes before the moment goes cold.
This is different from saying the model is thinking like a person. It is not. The person still supplies intent, taste, rejection, direction, and the final judgement.
The model supplies motion.
The faster the motion gets, the more of it can remain supervised.
The current fast lane
The public example I would start with is GLM 4.7 on Cerebras Code.
Cerebras positions GLM 4.7 as a coding model running at 1,000+ output tokens per second. Its migration docs list the Cerebras model ID as zai-glm-4.7, describe a roughly 358B-parameter mixture-of-experts model with about 32B active parameters, and note support for about a 131k context window with up to 40k completion tokens.
That combination is the point: capable enough to be useful, fast enough to change the shape of the interaction.
Cerebras fast lane
The public signal is not a leaderboard crown. It is a coding-capable model served quickly enough to keep loops close.
The private example is Kimi K2.6 on Cerebras.
Cerebras says Artificial Analysis measured Kimi K2.6 at 981 output tokens per second on 6 May 2026 through a private Cerebras endpoint. It also says a request with 10,000 input tokens and 500 output tokens completed in 5.6 seconds on Cerebras, compared with 163.7 seconds on the official Kimi endpoint in that test.
That is a serious number. It is also important to describe it accurately. Cerebras frames Kimi K2.6 as an enterprise customer trial / dedicated endpoint, not broad public self-serve access.
I do not want the article to become a Kimi post. Kimi is the measurement anchor. The bigger shift is that a trillion-parameter open-weight agentic model can be served quickly enough to feel interactive.
The Kimi K2.6 model card makes the scale clear: 1T total parameters, 32B active parameters, long context, multimodal input, tool use, and a Modified MIT licence. Those details matter. But the speed is what turns the details into a different product surface.
The interface gets exposed
Cerebras' own design guidance is unusually revealing here because it moves the conversation away from benchmark bragging.
At very high token rates, the UI can become the bottleneck. Rendering every streaming chunk can be slower than generation. Short answers may not need streaming. Multi-step agent loops that previously took 30 to 60 seconds can move closer to real time. Voice systems can become bottlenecked by speech-to-text and text-to-speech rather than the LLM call.
That is not a tiny implementation note.
That is the product admitting that the old theatre might be in the wrong place.
The source pass changes the claim from "this model is fast" to "the client, queue, and streaming assumptions now need redesigning".
GLM 4.7 migration docs
Model ID, context, output, and reasoning-mode details.
Cerebras design guide
UI buffering, streaming, agent loops, and voice latency implications.
Kimi K2.6 enterprise trial
981 output tokens per second through a private Cerebras endpoint.
If the model is slow, streaming is a kindness. If the model is fast, streaming can be a costume. It tells the user "work is happening" even when the work already happened and the browser is just catching up.
This is why fast inference feels like a product primitive. It changes what you bother building around the model.
The ceiling still belongs in the room
This is where I would be careful with the comparison.
GPT-5.6 Sol and Claude Fable 5 still belong in the picture. They are ceiling models: the systems I would reach for when judgement, reliability, difficult reasoning, long-running work, and final review are worth more than raw speed.
The July 9 update makes the trade-off more concrete. Artificial Analysis scores GPT-5.6 Sol at 80 on its Coding Agent Index and 54 on its Agentic Index, while Fable 5 remains narrowly ahead on general intelligence. OpenAI has also announced a separate selected-customer Cerebras route for Sol at up to 750 tokens per second. That is not broad self-serve availability, but it shows frontier quality and high-speed serving starting to converge.
So I would not turn this into a universal "Cerebras fast, Claude/GPT slow" argument.
The better frame is routing.
Use the fast model for motion. Use the ceiling model for judgement. Keep the human close enough to decide when the work should move from one lane to the other.
That feels closer to how I actually use these tools.
Sometimes I want the cleverest model in the room. Sometimes I want a very fast model to do the next six small moves while I am still looking at the problem.
Those are different jobs.
I built a speed lab for the feeling
The annoying thing about token speed is that it sounds abstract until you feel it.
So I built Inference Speed Lab as the companion piece. It is a small timing model, not a benchmark. The fast lane defaults to 981 output tokens per second because that is the Cerebras Kimi K2.6 enterprise-trial measurement. The comparison lane is adjustable because GPT-5.6, Claude, and other frontier systems vary by model, mode, effort, provider, prompt, context, and workload.
At 981 output tokens per second, 500 output tokens take about half a second of generation time. At 55 output tokens per second, the same output takes about nine seconds.
Nine seconds is still survivable for one answer.
It is different across a loop.
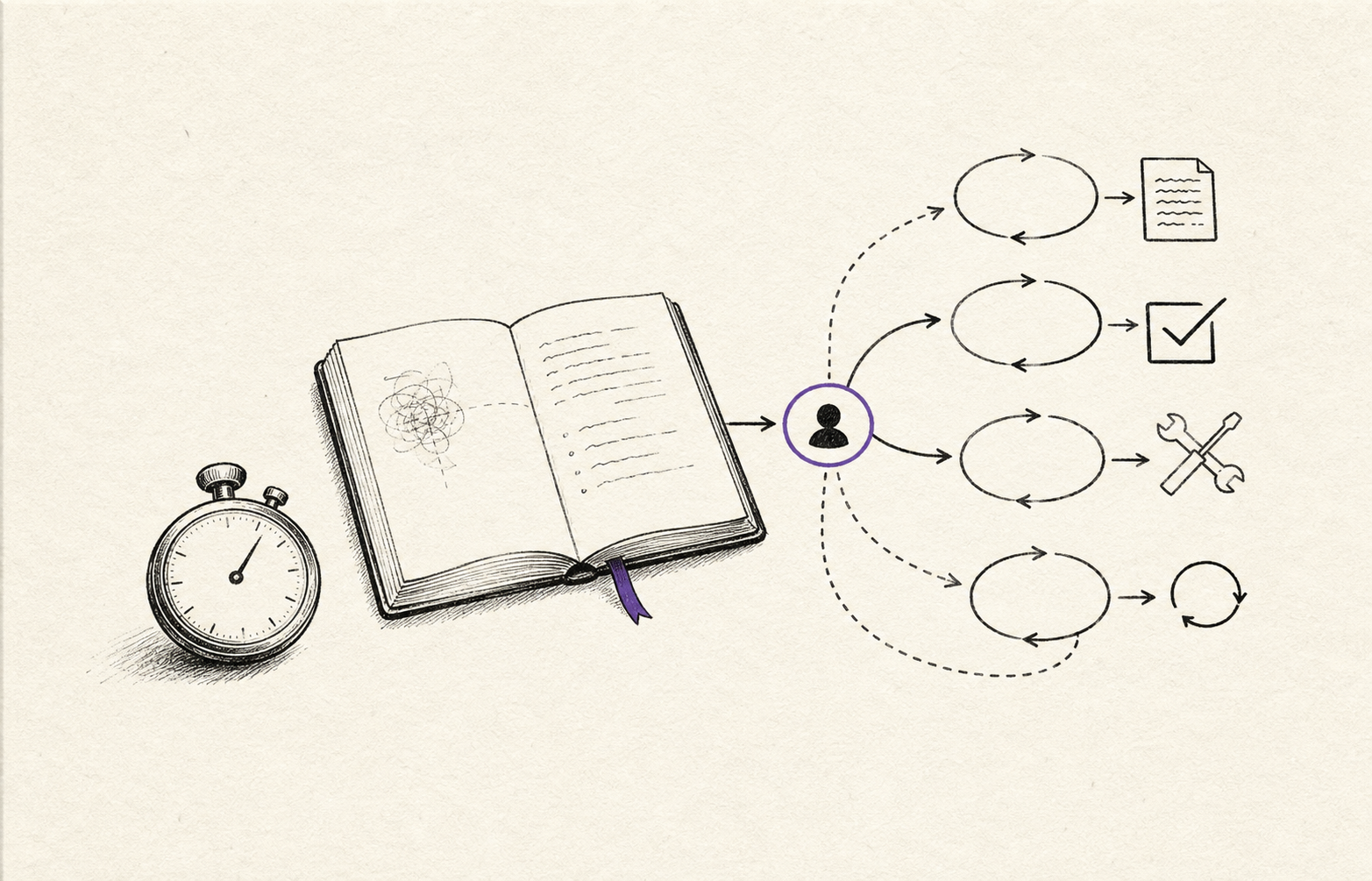
A fast supervised loop
One fast answer is the small version. The larger move is several bounded passes staying close enough for the human to steer.
Draft the first version
Produce the rough answer while the human still has the intent in mind.
Run the critic
Look for the risky assumption, missing source, or likely failure point.
Repair or escalate
Fix the ordinary weakness quickly, or route the hard judgement to a ceiling model.
Eight calls, each producing a few hundred tokens, can either feel like one interaction or like a background task. Add retrieval, tool calls, tests, and repair, and the difference becomes more than convenience. It changes whether the work remains supervised.
That is why the app belongs with the essay. It turns a benchmark-shaped claim into a small physical feeling: the fast lane keeps moving while the slower lane is still warming up.
Fast errors are still errors
There is a boring caveat here, but it is the caveat that keeps the argument honest.
Fast wrong answers are still wrong.
A model can produce a bad patch quickly. It can skip the one test that would have caught the problem. It can write plausible research notes that quietly overstate the evidence. A faster model with a weak loop is not a better system. It is just a more energetic one.
The useful pattern is speed plus verification.
If another pass is cheap in wall-clock time, the product can afford to ask:
- did this answer actually satisfy the instruction?
- what assumption would break it?
- which file, source, or test supports the claim?
- is this ordinary execution work or judgement work?
- should this move to a stronger model?
Those checks are where speed becomes useful. The model does more motion, but the system keeps asking whether the motion deserves to continue.
The future also gets faster
AI progress is usually described vertically.
Bigger model. Better benchmark. Higher ceiling.
That view is still useful, and I keep writing about it. But it misses the horizontal change: how much useful model work can happen inside a normal human moment.
That is why Cerebras feels interesting beyond the IPO. The company is pointing at a faster chip and a faster endpoint, but the part that feels more durable is the rhythm it creates for AI software.
The old rhythm was:
Ask. Wait. Review. Retry.
The new rhythm starts to look more like:
Draft. Check. Repair. Compare. Escalate. Return.
That second rhythm is closer to actual thinking with a tool. It is messy, iterative, and supervised. It does not remove the human. It gives the human more chances to steer before the thread breaks.
That is the version of the future that feels most concrete to me right now.
Not one magic answer.
More useful loops before you lose the thought.
Try this prompt
Pick one workflow I currently use AI for. Split it into the fast-motion parts and the judgement parts. For the fast-motion parts, design a loop that drafts, checks, repairs, and summarises before I lose attention. For the judgement parts, name when the work should escalate to a stronger model or back to me. End with the smallest version I could test this week.
Related on this site
- Inference Speed Lab is the companion timing model for feeling the gap between near-1,000-token-per-second inference and slower repeated loops.
- The Floor and Ceiling of AI is the related frame for understanding open model capability against the proprietary frontier.
- AI Is Moving From Chatbots to Operating Systems explains why model quality now needs to be understood alongside tools, agents, and workflow architecture.
Sources
- Cerebras IPO filing announcement
- Cerebras Code GLM 4.7 page
- Cerebras GLM 4.7 migration docs
- Cerebras design guide for ultra-fast inference
- Cerebras Kimi K2.6 enterprise-trial measurement
- Kimi K2.6 model card
- OpenAI GPT-5.6 general availability
- Artificial Analysis GPT-5.6 benchmarks
- Anthropic Claude Fable 5 announcement