Most conversations about AI progress focus on the ceiling.
Which proprietary model is strongest right now? Which lab is ahead? Is the best coding model GPT-5.6 Sol, Claude Fable 5, Grok 4.5, or something else depending on the task?
That is useful, but it misses the part that feels more historically important.
The better question is what is happening to the floor.
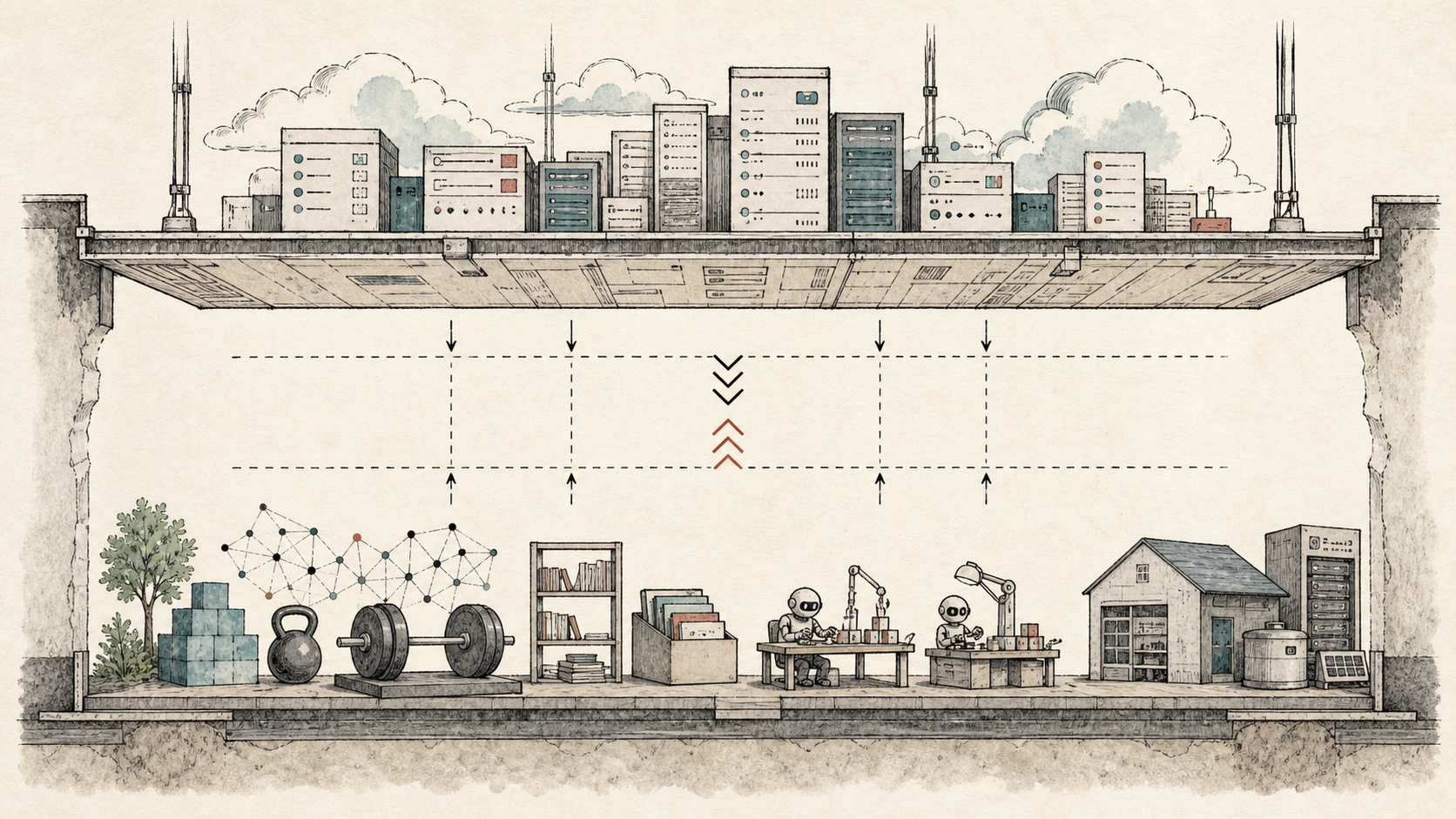
By floor, I mean the strongest open-weight or open-source AI available at a given point in time. If the proprietary frontier collapsed tomorrow, if the APIs disappeared or access was cut off, what is the minimum capability the world would still have?
That is the floor.
The ceiling tells you what is possible at the top end. The floor tells you what cannot be put back in the bottle.
I built a small companion tracker for this idea here: Floor / Ceiling. It is meant to become a monthly record of the open floor and proprietary ceiling, rather than another loose list of model launches.
The tracker uses Artificial Analysis for the points and gap, rechecked on 10 July 2026: Coding Agent Index for coding, Agentic Index for agentic work, and Intelligence Index for general reasoning. The floor and ceiling model choices are still editorial, but each displayed side uses the highest comparable AA score among its listed models. Vendor-only results stay visible as candidates without moving the gap.
July 2026 update: the ceiling now splits by domain. Artificial Analysis scores GPT-5.6 Sol (max) at 80 on Coding and 54 on Agentic work, so Sol replaces Fable 5 as the measured ceiling in those two tracks. Claude Fable 5 remains narrowly ahead on general intelligence at 59.9 versus Sol's 59. Terra, Luna, and Grok 4.5 deepen the measured proprietary cohort. GLM-5.2 remains the measured open floor across all three domains, while LongCat-2.0 and the official Tencent Hy3 release remain unscored open-floor candidates for their exact versions. Muse Spark 1.1 is a new agent and computer-use ceiling candidate, but its current benchmark table is first-party, so it does not set an independent gap yet.
June 2026 update: the tracker now has a refreshed live snapshot. Claude Fable 5 has replaced Opus 4.8 as the measured public ceiling after Anthropic's 9 June release. Artificial Analysis scores Fable 5 at 59.9 on the Intelligence Index, 76.5 on Coding, and 52.8 on Agentic work, making it the current benchmark anchor in all three tracker domains. Claude Mythos 5 matters too, but I am not counting it as the public ceiling because Anthropic restricts it to Project Glasswing and future trusted-access programs rather than broad availability. Sakana Fugu Ultra now belongs in the ceiling conversation as well, but as an unscored commercial orchestration layer rather than the measured benchmark anchor.
GLM-5.2 is now public. Z.AI has released the weights under an MIT licence, with a 744B-total / 40B-active MoE shape, 1M context, flexible reasoning effort, and local serving paths through SGLang, vLLM, Transformers, and KTransformers. Z.AI's GLM-5.2 docs list 1M context and 128K max output, and Z.AI pricing lists $1.40 input, $0.26 cached input, and $4.40 output per million tokens. Artificial Analysis scores GLM-5.2 at 51.1 on Intelligence, 68.8 on Coding, and 43.1 on Agentic work, so it now sets the measured open floor in the June tracker. AA's provider page now tracks 11 GLM-5.2 providers, with Baseten fastest at 284.9 output tokens per second and GMI (FP8) cheapest at $0.72 blended per million tokens.
There is also a closed-model wrinkle now: Sakana Fugu Ultra. Sakana frames Fugu as a single OpenAI-compatible API that dynamically coordinates a pool of expert models. Fugu is the lower-latency default, while Fugu Ultra maximizes quality on harder multi-step problems and can route through one to three expert agents. Sakana reports Fugu Ultra at 73.7 on SWE Bench Pro, 82.1 on TerminalBench 2.1, 93.2 on LiveCodeBench, 90.8 on LiveCodeBench Pro, 50.0 on Humanity's Last Exam, and 95.5 on GPQA-D. Its pricing page lists $5 input, $30 output, and $0.50 cached input per million tokens for Fugu Ultra, with higher rates above 272K context. Artificial Analysis does not list Sakana or Fugu as of my 22 June 2026 recheck, so I am treating it as a proprietary orchestration-ceiling candidate, not an open floor model, and not a replacement for the AA-derived floor/ceiling numbers yet.
MiniMax M3 remains a June general-floor candidate if you count MiniMax's announced open-weight release. Artificial Analysis now scores MiniMax-M3 at 44.4 on the Intelligence Index. The caveat is that MiniMax's own page still says full Hugging Face and GitHub release is coming soon, while AA currently labels the weights as unavailable, so a strict downloadable-weights view should wait for the public weights. Nemotron 3 Ultra is included too: AA scores it at 37.8 on the Intelligence Index and lists it as a 550B total, 55B active, open-weights model.
Kimi K2.7-Code is the new open coding-floor addition. Moonshot released public weights under a modified MIT licence, kept the 1T-total / 32B-active MoE shape and 256K context, and reports stronger long-horizon coding performance with about 30% lower thinking-token usage than K2.6. I am treating it as a floor candidate now, but I am not moving the displayed AA gap until an independent score lands.
The other latest open-model additions do not set the floor. North Mini Code is an Apache-2.0 30B-total / 3B-active coding MoE, but its 33.4 AA Coding Index signal is below the current open coding floor. Gemma 4 12B brings laptop-scale open multimodality across text, image, audio, and video. DiffusionGemma 26B A4B is a stranger architectural signal: an Apache-2.0 diffusion language model that trades token-by-token generation for parallel denoising and much higher output speed.
The ceiling in April 2026
As of late April 2026, I would put two systems in the ceiling conversation.
OpenAI's GPT-5.5 Pro is listed in OpenAI's model docs as a high-compute version of GPT-5.5, available through the Responses API, with a 1,050,000-token context window and 128,000 max output tokens.
Anthropic announced Claude Opus 4.7 on 16 April 2026. Anthropic describes it as available across Claude products, the API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry, with the claude-opus-4-7 model ID.
Those are ceiling models in the obvious sense. They are expensive relative to smaller systems. They sit behind proprietary services. They are the sort of models you reach for when the work is hard enough that reliability, depth, and supervision cost matter more than the token bill.
For coding, the exact winner probably depends on the work. Claude Opus 4.7 looks especially strong for long-running software engineering and agentic workflows. GPT-5.5 Pro is the parallel OpenAI ceiling for hard reasoning, coding, and professional work.
But the ceiling is not the whole story.
The floor is already high
Now look at what is openly available.
DeepSeek V4 Pro is on Hugging Face as a DeepSeek V4 preview model. The model card describes it as a mixture-of-experts model with 1.6 trillion total parameters, 49 billion activated parameters, a 1-million-token context length, and an MIT licence.
Xiaomi MiMo V2.5 Pro is also on Hugging Face. Xiaomi describes it as an open-source MoE model with 1.02 trillion total parameters, 42 billion active parameters, up to a 1-million-token context length, and an MIT licence. The model card is explicit about its target: agentic work, complex software engineering, and long-horizon tasks.
GLM-5.1 belongs in the April floor too. Z.AI lists GLM-5.1 in its 7 April 2026 release notes and frames it around long-horizon agentic engineering. The Hugging Face model is under an MIT licence.
Kimi K2.6 is another late-April floor candidate. Moonshot's model card calls it an open-source, multimodal, agentic model, with 1 trillion total parameters, 32 billion active parameters, a 256K context length, and a modified MIT licence.
Ling-2.6-1T now belongs on the same watchlist. InclusionAI's Hugging Face repo lists an MIT licence and 1.026 trillion parameters, and its config uses a 262K context window. The model card frames it around lower token overhead, tool calling, coding, and reliable multi-step execution. Artificial Analysis currently gives it a 34 Intelligence Index score, so it is more a fresh open-floor signal than the model that sets the April gap.
That is a strange sentence if you remember where the field was three years ago.
A consumer electronics company has released a trillion-parameter open model aimed at agentic software work. DeepSeek has released another trillion-scale open model with a million-token context window. Z.AI, Moonshot, and InclusionAI are pushing the open floor directly into long-running engineering agents. All of this is sitting behind normal Hugging Face links.
This is what I mean by the floor.
It is not a weak backup. It is not a small local model that can autocomplete a function if you hold it carefully. It is a serious capability layer. If the proprietary frontier vanished, the world would not fall back to early ChatGPT. It would fall back to open trillion-scale models with long context, permissive licences, and enough capability to keep a lot of AI work moving.

Why the floor matters more than it sounds
The ceiling moves first because frontier labs have more compute, more capital, and more control over the whole stack. A new capability usually appears there first.
But capabilities migrate downward.
Long context used to be a frontier differentiator. Now open models are claiming million-token windows. Strong coding used to sit mostly with closed systems. Now the open floor is clearly targeting complex coding agents. Tool use, reasoning traces, instruction following, agentic loops, and efficient MoE serving have all moved from rare frontier capability into the open ecosystem.
That migration changes the shape of the AI argument.
If a capability only exists in a closed lab, it is fragile. It can be rate-limited, repriced, regulated, withdrawn, or region-locked. Once the weights are public and the licence is permissive, the capability becomes part of the technical environment. It can still be hard to run. It can still be expensive. It can still be weaker than the ceiling. But it is no longer held in one place.
This is why I do not think there is a realistic return to pre-AI times.
You can imagine policy changes, market corrections, lab failures, API bans, or product reversals. None of those remove the models already released. The weights are distributed. The serving stacks improve. Quantisation gets better. Fine-tunes appear. Tooling grows around the models. Teams learn how to use them.
The floor has its own momentum now.
The gap is real
This does not mean the floor and ceiling are the same.
If I had to run a difficult production migration, review a subtle codebase change, or hand off a long research task where mistakes are expensive, I would still start with the measured ceiling. GPT-5.6 Sol now leads the measured coding and agentic tracks, while Claude Fable 5 keeps the general-intelligence lead. Terra, Luna, and Grok 4.5 deepen the measured closed-model cohort. Muse Spark 1.1 and Sakana Fugu Ultra belong on the same watchlist, though I would treat their current vendor-reported results as unmeasured until comparable independent scores land. These systems will usually have better product scaffolding, safer defaults, stronger tool integration, and more consistent performance.
The gap still exists.
The point is that the gap is no longer the difference between "AI" and "no AI". It is the difference between the best available AI and the best openly available AI.
That distinction matters.
Once the floor is high enough, a lot of work becomes durable. A school, small company, solo developer, research group, or country without clean access to proprietary APIs can still build with capable models. Not always at the ceiling. But far above the old baseline.
That is the part that changes the world underneath the model leaderboard.
Track the floor monthly
The useful thing to watch now is not a single snapshot. It is the trajectory.
Some months the ceiling jumps and the gap widens. Then the floor catches up. Sometimes the open model is not broadly better, but it becomes good enough in one domain: coding, long context, maths, search, agents, multimodal work. Those domain-specific jumps are how the floor rises.
That is why I want the Floor / Ceiling tracker to be monthly.
The question each month is simple:
- What is the current proprietary ceiling?
- What is the current open floor?
- Which domain moved: coding, general reasoning, agents, multimodal work?
- If the ceiling disappeared, what would still be possible?
That last question is the one I care about.
The ceiling tells us where the frontier is. The floor tells us what the world already has.
Right now, for coding and agentic work, the open-floor cohort includes GLM-5.2, LongCat-2.0, Tencent Hy3, Kimi K2.7-Code, MiniMax M3, Nemotron 3 Ultra, Kimi K2.6, GLM-5.1, DeepSeek V4 Pro, Xiaomi MiMo V2.5 Pro, and Ling-2.6-1T. GLM-5.2 sets the measured floor; LongCat-2.0 and the official Tencent Hy3 release remain candidates until comparable exact-version scores land. North Mini Code, Gemma 4 12B, and DiffusionGemma 26B A4B are research notes below that floor. The measured public ceiling now splits between GPT-5.6 Sol for coding and agentic work and Claude Fable 5 for general intelligence, with Terra, Luna, and Grok 4.5 as measured context and Muse Spark 1.1 plus Sakana Fugu Ultra as vendor-reported candidates.
That is not a return-to-normal situation. That is a permanently changed baseline.
Try this prompt
Pick one AI capability and estimate its floor and ceiling. Define the proprietary frontier version, the strongest open or widely available alternative, the practical gap between them, and which parts of the workflow would still survive if the frontier disappeared tomorrow. End with what this changes about my dependence on closed models.
Related on this site
- Floor / Ceiling is the interactive tracker for the monthly open floor and proprietary ceiling.
- The Evolution of LLMs gives the broader model-history view behind the current frontier.
- AI Is Moving From Chatbots to Operating Systems explains why model quality now has to be understood alongside tools, agents, and workflow architecture.
Sources
- Claude Fable 5 and Claude Mythos 5 announcement
- Claude Fable 5 and Claude Mythos 5 API docs
- Claude Fable 5 on Artificial Analysis
- Kimi K2.7-Code on Hugging Face
- Kimi K2.7-Code on Cloudflare Workers AI
- Z.AI GLM-5.2 model docs
- Z.AI GLM-5.2 pricing
- GLM-5.2 on Hugging Face
- GLM-5.2 on Artificial Analysis
- GLM-5.2 provider benchmarks on Artificial Analysis
- Artificial Analysis GLM-5.2 release analysis
- Sakana Fugu release announcement
- Sakana Fugu model page
- Sakana Fugu console models
- Sakana Fugu pricing
- GPT-5.5 Pro model docs
- Claude Opus 4.8 announcement
- Claude Opus 4.8 API docs
- Claude Opus 4.7 announcement
- MiniMax M3 model page
- MiniMax M3 research post
- MiniMax-M3 on Artificial Analysis
- Nemotron 3 Ultra on Artificial Analysis
- NVIDIA Nemotron 3 Ultra announcement
- North Mini Code docs
- North Mini Code on Hugging Face
- Gemma 4 12B announcement
- DiffusionGemma developer guide
- DiffusionGemma on Hugging Face
- Qwen3.7 Plus on Artificial Analysis
- DeepSeek V4 Pro on Hugging Face
- Xiaomi MiMo V2.5 Pro on Hugging Face
- GLM-5.1 on Hugging Face
- Z.AI release notes for GLM-5.1
- Kimi K2.6 on Hugging Face
- Kimi K2.6 tech blog
- Artificial Analysis model benchmarks