People keep saying they want agents to talk to each other.
That sounds simple until you look at how the better systems are actually built.
Most multi-agent systems are not agents sitting around in an open-ended conversation. They are much narrower than that. One agent reviews another. One agent hands a task to a specialist. Several agents write into the same shared thread. Or separate agent systems discover each other through a protocol and exchange task updates over HTTP.
The phrase flattens several different architectures into one bucket.
Some of them are mainly about context control. Some are about review and dissent. Some are about task routing. Some are about interoperability between products, teams, or companies. If you flatten those into one idea, you miss the design choices that decide whether the system works.
The useful pattern across nearly all of them is that the systems work better when the exchange is constrained.
The strongest agent-to-agent setups don't rely on endless free chat. They rely on shared artefacts, typed handoffs, bounded roles, explicit termination rules, and proof of work.
I also think this is probably the next real step in agent systems.
To me, the interesting move isn't another subagent feature trapped inside one vendor stack. It's genuine multi-agent runtime across different harnesses. If Codex, Claude Code, and Gemini CLI can all work in the terminal, use tools, keep state, and act on the filesystem, the obvious next move is not to force one of them to own the whole task. It is to let them coordinate directly through review channels, handoffs, shared artefacts, or protocol boundaries.
Subagents are usually not the same thing
It helps to clear one confusion out first.
When most coding tools or agent frameworks talk about subagents, they usually mean internal delegation inside one larger system. OpenAI's Agents SDK draws a clean line between a manager pattern, where specialist agents are exposed as tools, and a handoff pattern, where control moves to another specialist. LangChain's multi-agent docs make a similar distinction, and describe handoffs as state-driven transitions rather than general chatter between peers.
That's useful, but it is not quite the same as independent agents talking to each other as agents.
In the subagent pattern, one runtime still owns the work. The outer system decides what to call, what state to pass, and what comes back. It's closer to structured delegation than peer communication.
The more interesting systems start once the agents are allowed to exchange review, transfer ownership, contribute to a shared thread, or negotiate through a protocol boundary.
1. Paired peers and review bridges
One of the clearest recent examples is loop, which Axel Delafosse published on 26 March 2026 alongside his short note on agent-to-agent pair programming.
loop is deliberately narrow. It is not trying to be a universal agent framework. The repository describes it as a "meta agent loop" that runs codex and claude side by side in tmux, keeps both sessions persistent, bridges messages between them, and iterates against a shared PLAN.md until the work is completed.
This is the interesting part.
Instead of treating the second agent as a hidden tool, loop treats it as a reviewer and support agent with its own persistent session. The main worker does the implementation. The other agent critiques, reviews, and pushes back. When both reviewers agree on a problem, Delafosse argues that this is often a strong signal that the issue is real. The CLI also keeps run state under ~/.loop/runs/..., supports resume by run id or session id, and emphasises explicit proof requirements rather than vague completion.
This is closer to pair programming than orchestration.
The agents are not merely invoked. They are in a loop with each other, and the shared object is not the raw transcript but a small set of common artefacts: the repo, the PLAN.md, the local run state, the review comments, and eventually the draft PR.
The pattern is promising because it gives you disagreement without requiring a human to manually relay every message. It also gives each model a reason to specialise. One can push the change forward while the other tries to break the argument, challenge the diff, or ask for stronger proof.
It also points beyond one framework's internal team feature. loop is interesting because it bridges harnesses. Today that means Codex and Claude. The same general pattern could extend to Gemini CLI or other terminal-first agents as long as they can persist sessions, exchange bounded messages, and inspect the same working state.
Practical guidance: use this pattern when you want friction inside the loop. Give the pair one small shared artefact such as a plan, checklist, or PR diff. Require explicit proof. Treat agreement as signal, not truth. If both agents can say anything about everything, the loop becomes noise very quickly.
2. Embedded bridge plugins inside one harness
One reason this space now feels more real than speculative is that the bridge is starting to become a product feature.
OpenAI's codex-plugin-cc is the clearest example so far. The repository describes it as a Claude Code plugin that lets you use Codex from inside Claude Code for code review or delegated tasks. It adds /codex:review, /codex:adversarial-review, /codex:rescue, /codex:status, /codex:result, /codex:cancel, and /codex:setup, and it also installs a codex:codex-rescue subagent inside Claude Code.
The architecture is more important than the slash commands.
According to the README and plugin files, this is not a separate hosted bridge. It wraps the local Codex app server, uses the same machine-local codex CLI install, shares the same repository checkout, respects the same Codex config, and can move work into background jobs that Claude later checks with /codex:status and /codex:result. The optional review gate goes even further: it installs a Stop hook that runs a targeted Codex review of Claude's previous turn and can block session end if Codex still sees issues.
That's a meaningful shift.
This is not protocol-level interoperability like A2A, and it is not a fully equal peer loop like loop. It is an embedded cross-harness bridge where Claude Code remains the outer runtime and Codex becomes an integrated second agent with its own job lifecycle, review path, and resumable sessions.
That makes it one of the better real-world signs that cross-harness runtime is becoming practical. The second harness doesn't disappear into a tool call. It keeps enough of its own runtime identity to be useful.
Practical guidance: use this pattern when one harness is clearly your primary workspace and you want to pull another agent in for review, rescue work, or stop-time pressure testing. It is strong for asymmetric pairing. It is weaker as a general interoperability model, because Claude still owns the outer loop and the integration stays local to one machine and one repo checkout.
3. Handoffs are not really conversation
The cleanest way to make agents "talk" is often to avoid conversation almost entirely.
That's the logic behind handoffs.
In OpenAI's handoffs guide, an agent can delegate part of a conversation to another agent through a dedicated tool such as transfer_to_refund_agent. The SDK also supports small structured handoff payloads, filtered history, and explicit routing metadata. The receiving agent does not need to see the full internal reasoning of the previous one. It only needs the right context to take over.
LangChain's handoff documentation pushes the same idea even further. It describes handoffs as state-driven behaviour: tools update variables such as current_step or active_agent, and the system changes prompts, tools, or routing accordingly. That is not social exchange. It's controlled state transition.
This is a good thing.
Most failures in multi-agent systems come from passing too much context, not too little. If one agent dumps raw scratchpad, half-finished tool chatter, and irrelevant history into the next agent's prompt, the receiving agent inherits confusion instead of help.
Handoffs work because they minimise the surface of the exchange.
The message is effectively: this specialist should own the task now, here is the small amount of context required, continue from here.
Practical guidance: use handoffs when one specialist should take full control for a while. Keep the payload short and typed. Filter history aggressively. If you need an agent to justify the transfer, ask for a one-sentence summary and a routing reason, not its whole chain of thought.
4. Shared-thread group chat
Some systems take the opposite approach.
Instead of transferring ownership from one agent to another, they keep several agents in one shared conversational space and let them build on the same visible history.
AutoGen's SelectorGroupChat is a good example. The docs describe it as a team where participants take turns broadcasting messages to all other members, while a model selects the next speaker based on the shared context. In the official example, a planning agent breaks the task into subtasks, a web search agent retrieves information, a data analyst agent performs calculations, and the group stops when a termination condition is reached.
This pattern can work well when the shared thread itself is the working memory.
Everyone sees the same assignments. Everyone sees the same partial results. The planner can revise the plan based on what the specialists have already produced. If the task is naturally collaborative and the context fits comfortably inside the budget, this can feel surprisingly effective.
But it also carries obvious risks.
Broadcast history grows quickly. Roles blur. Agents start talking past each other. A selector model may choose the wrong next speaker. The more open the discussion becomes, the more likely it is that the system mistakes activity for progress.
The better group-chat systems respond by keeping the role descriptions tight, the task surface narrow, and the termination conditions explicit.
Practical guidance: use shared-thread group chat when the agents genuinely need common public context. Give one agent planning authority. Give the others narrow capabilities. Cap the number of turns. If the conversation starts resembling a meeting, the structure is probably too loose.
5. Swarms let agents make local routing decisions
There is another design that sits between handoffs and group chat.
AutoGen's Swarm pattern describes a team in which agents hand off tasks to other agents based on their capabilities, while still sharing the same message context. The docs frame this as a pattern first introduced by OpenAI Swarm, with one important difference from manager-led systems: local agents decide when to hand the task onward rather than waiting for a single central orchestrator to do all the routing.
That changes the feel of the system.
In a selector-led group chat, the manager or selector model chooses who speaks next. In a swarm, each speaker can decide who should take over after them. The routing logic is more distributed. The official AutoGen docs call this out directly: agents make local decisions about task planning instead of relying on a central orchestrator.
This can be useful when the task path is not fully predictable up front.
A travel agent can hand off to a flight refunder. That specialist can hand off to the user for missing details. Then control can move back to the travel agent to finish the interaction. The conversation still lives in one shared context, but ownership can move more fluidly.
The trade-off is that you lose some global discipline.
If too many agents can hand off to too many others, the system becomes hard to reason about. The shared context helps, but it also means every weak handoff decision pollutes the next turn.
Practical guidance: use swarm-style systems when local agents should own sequencing as well as execution. Keep the handoff graph small. Make allowed destinations explicit. Add strong termination conditions, because otherwise a swarm can keep moving without actually closing the task.
6. Protocols between independent agents
The closest thing to genuine agent-to-agent communication is not a chat framework at all.
It is a protocol.
The Agent2Agent Protocol is the clearest example of that shift. The project describes A2A as an open protocol that enables communication and interoperability between opaque agentic applications. The official docs and README both emphasise a goal broader than tool calling: separately built agents should be able to discover each other, understand capabilities, negotiate interaction, and collaborate on tasks without exposing internal memory, state, or tools.
The opaque boundary is the important bit.
Once agents live in different stacks, products, or organisations, you can no longer assume one runtime owns the whole exchange. You need a discovery layer, a capability description, an authentication story, task lifecycle semantics, and a transport that works across normal web infrastructure.
That is what A2A is trying to provide.
The A2A discovery docs describe an Agent Card as a JSON document that acts like a digital business card for an agent server. It includes identity, endpoint, capabilities, authentication requirements, and skills. The v1.0 announcement says the protocol now supports multi-protocol bindings, version negotiation, signed Agent Cards, multi-tenancy, and standard web patterns such as polling, streaming, and webhooks. The official A2A and MCP comparison is also useful here: MCP is for tools and resources inside an agent, while A2A is for collaboration between agents.
This is a different category from subagents or local handoffs.
At this layer, "talking" means capability discovery, task submission, status updates, and exchange of structured artefacts across trust boundaries. It is less like a brainstorm and more like a durable service contract between autonomous systems.
Practical guidance: use a protocol-level approach when the agents are genuinely independent. Publish narrow skills, not vague promises. Assume asynchronous execution. Sign or protect discovery metadata where trust is part of the exchange. Don't expose internal state unless the receiving agent truly needs it.
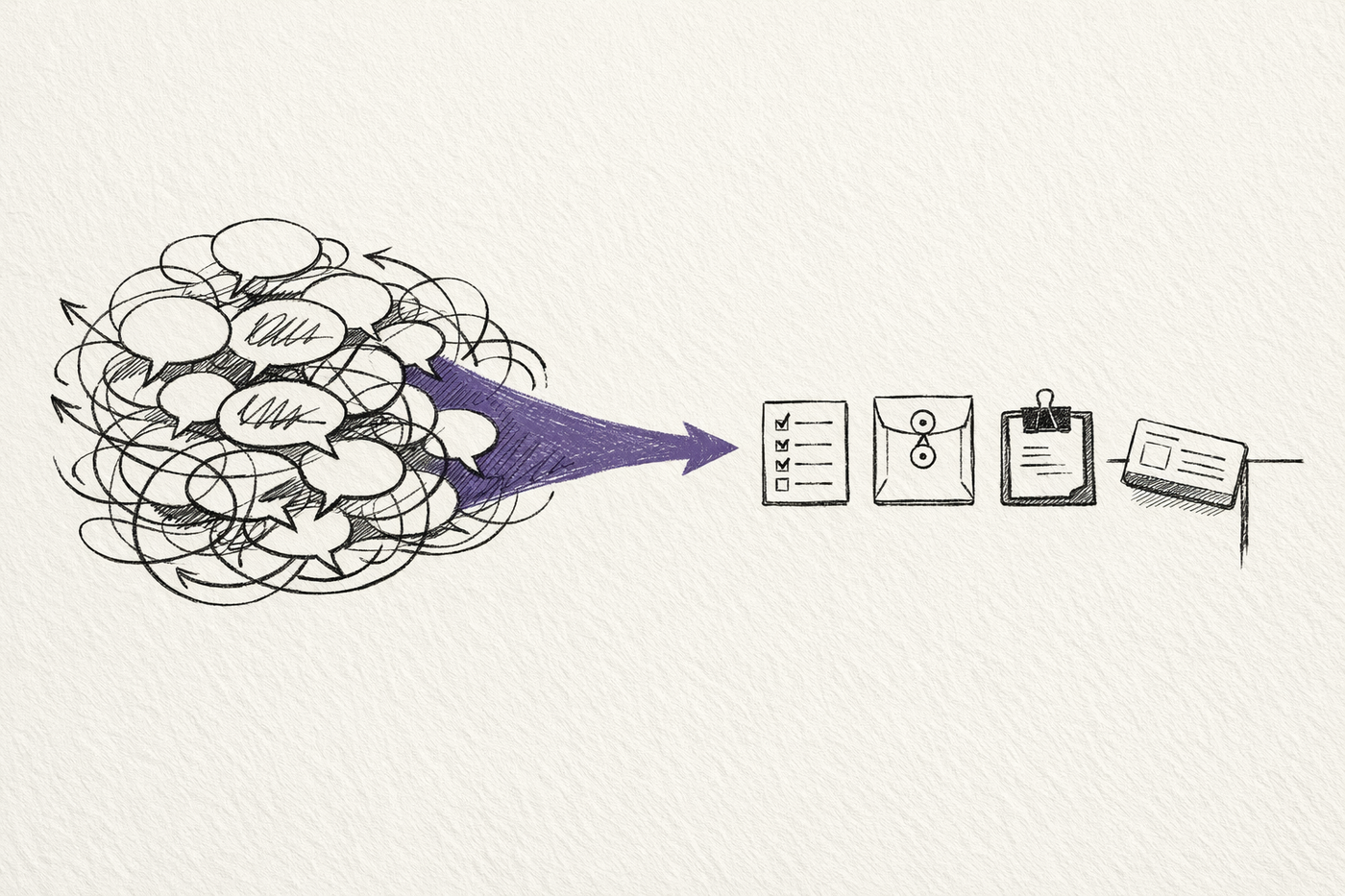
What actually works
Once you look across these systems together, a pattern becomes hard to miss.
The useful ones do not treat agent communication as open-ended dialogue.
They reduce it to a few well-behaved forms:
- a shared artefact such as
PLAN.md, a checklist, or a PR diff - a typed transfer that changes who owns the task
- a shared public thread with clear roles and termination rules
- a capability document such as an Agent Card
- a proof or evaluation step that decides whether the exchange helped
So I don't think the useful question is "can agents talk to each other?"
They already can.
The better question is what kind of interface should exist between them.
If the answer is "let them chat more", the system usually gets worse.
If the answer is "give them a small, legible contract for review, transfer, or capability discovery", the system gets much more usable.
This is also where agent memory and evaluation come back into view. Once work moves between agents, the problem stops being only model capability. It becomes a systems problem about what state persists, what gets summarised, what gets filtered, and how the next agent can tell whether the last agent actually improved the work.
The stronger multi-agent patterns end up looking less like conversation design and more like workflow design.
That's why I think genuine cross-harness runtime is the next serious step.
Once Codex, Claude Code, Gemini CLI, and similar agents all have their own strengths, their own tool surfaces, and their own operating styles, it makes less sense to ask which one should own the entire loop. The more practical move is to let them collaborate under explicit contracts. One agent reviews. Another routes. Another handles search or long context. Another owns the final action. Runtime becomes the coordination layer.
The agents do talk.
But the systems that last are the ones where the conversation has been turned into structure.
Try this prompt
Design a multi-agent workflow for a real project. Choose whether it should use paired peers, a review bridge, a handoff, a shared thread, a swarm, or an open protocol. Explain why that pattern fits the work, what context each agent gets, how disagreement is resolved, and what artifact proves the loop improved the result.
Related on this site
- Five Levels of Running Claude Code More Autonomously is the closer companion if you want to think about loops, review passes, and proof-based autonomy in coding agents.
- Agent Memory Is Being Built Around the Model covers the other half of this problem: what state gets stored, filtered, and reintroduced once multiple agents or sessions need continuity.
- AI Evaluation Checklist is the short review layer I keep coming back to when an agent system looks busy and I need to ask the harder question: did the last step actually help?
Sources
- loop repository
- Agent-to-agent pair programming
- Claude Code overview
- Codex plugin for Claude Code
- Codex app server
- Gemini CLI repository
- OpenAI Agents SDK: Agents
- OpenAI Agents SDK: Handoffs
- OpenAI Swarm repository
- LangChain multi-agent handoffs
- AutoGen SelectorGroupChat
- AutoGen Swarm
- Agent2Agent Protocol repository
- A2A Protocol v1.0 announcement
- A2A Agent Discovery
- A2A and MCP