The recent Supermemory research post is interesting, though AI memory inherently remains unsolved.
It's probably better to say that agent memory is becoming an architecture problem for AI users, rather than one for AI researchers to solve in the short to medium term.
Large language models still do not remember in any practical sense. They process a context window, produce an answer, and only retain what's in their existing context window. If a system appears to remember across sessions, it is because something outside the base model stored, filtered, updated, and reintroduced the right information at the right time (which OpenAI and Claude have implemented behind the scenes, since early to mid 2025).
I do have an interactive explainer on the recent concepts around this: Agent Memory Architecture.
According to Supermemory's reported results on LongMemEval, its system outperforms both full-context baselines and Zep on knowledge updates, temporal reasoning, and multi-session recall.
What Supermemory describes is a layered memory architecture: chunking conversations into smaller units, extracting memories from those units, attaching temporal metadata, tracking relations such as updates, extends, and derives, then retrieving the higher-signal memory first before bringing back the original source chunk when a model believes it needs to reference the past.
It's not the same as a large language model that is able to 'learn' naturally from each conversation. It's more of a system that makes a stateless model behave as if it can remember.
Honestly, it's is a promising direction to explore, especially for those who don't work in the AI research field.
Software rarely solves a hard limitation by waiting for one component to become perfect. SQL Databases exist because we need a place to store long-term memories, while indexes for those databases exist because brute-force search is too slow on larger databases. We even create caches because recomputing everything can be wasteful and inefficient. Agent memory is heading the same way, where our workarounds are becoming some sort of solution.
The model is still stateless
If memory simply meant putting more history an existing conversation, long context windows would already have solved most of this, yet they haven't really.
Long prompts are expensive, noisy and make it harder to separate what is current from what is merely similar. My personal experience with Gemini 3.1 Pro and what I would call 'steerability' suggests that even with advanced models, distinguishing between current and outdated information remains a challenge (though less of one compared to even a year ago). A meeting transcript can easily contain both the old fact and the new one, a previously cancelled meeting and the rescheduled one, both the earlier preference and the revised one. Similarity alone does not tell the system which state should govern the present.
Hence, why it is important to have a versioning layer in any memory architecture for large language models.
If a user says in January that they live in Melbourne and in March that they moved to Sydney, a useful memory system should know that one fact superseded the other. The same can be said for general metadata like project status, team roles, travel plans, budgets, deadlines, and preferences. Useful agent memory bridges the gap between basic recall and 'state transition'.
Temporal grounding is also important, as an agent needs to know both when something was recorded and when the event itself occurred. Those are not always the same date, and confusing them produces exactly the kind of errors that make agents feel careless (or overconfident).
Why embeddings still matter
This is also why I don't think new memory systems make embeddings obsolete. If anything, Gemini Embedding 2 pushes the opposite direction.
On 10 March 2026, Google introduced Gemini Embedding 2 in public preview as its first natively multimodal embedding model. Google says it maps text, images, video, audio, and documents into a single embedding space, supports interleaved multimodal inputs, and can capture semantic intent across more than 100 languages.
It's a very important step in building useful agents as they no longer rely only on chat history (text and words).
Production agents may need to retrieve a screenshot, a voice note, a short video clip, a PDF, a conversation excerpt, and a structured note, then connect them inside one working context. A text-only embedding layer has always lacked the nuance of image recognition and multimodal objects. A multimodal embedding layer makes the recall step much broader and more natural.
Memory for large language models has also been redefined, as it is no longer only what the user said as text. It can be what the user showed, uploaded, recorded, annotated, or pointed at.
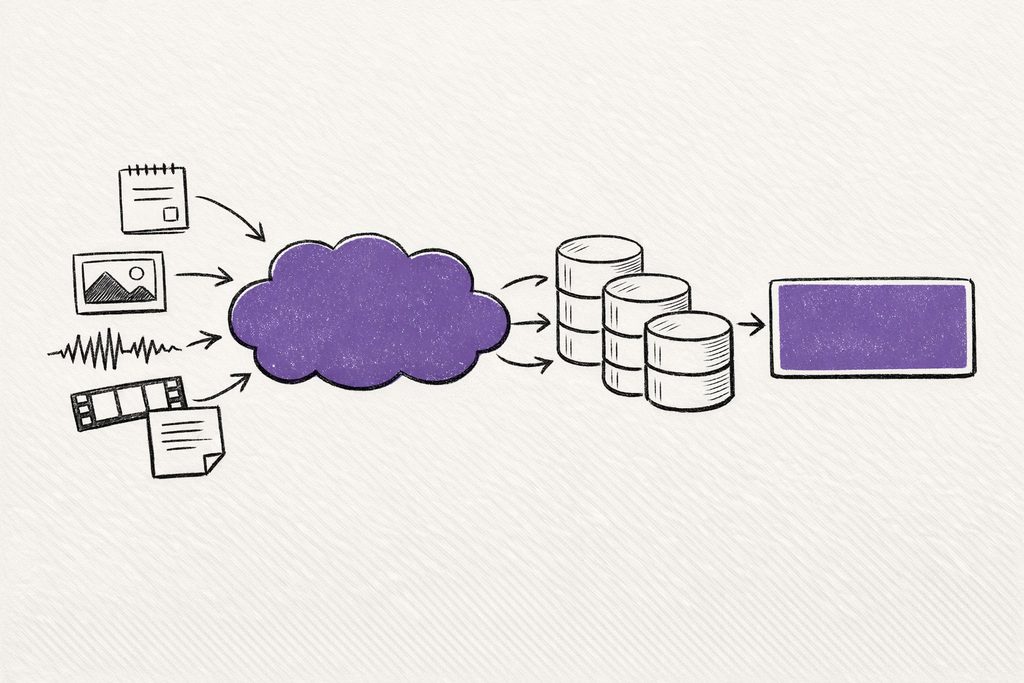
But embeddings were never the whole answer
Yet none of this removes the hardest part.
An embedding model can tell you that two things are related. It's much weaker at deciding whether one replaces the other, whether a fact is stale, whether a note was only relevant for one session, or whether a piece of evidence should be treated as current state or historical background.
This is why a pure vector store retrieval-augmented generation agent often feels impressive in demos and pretty unusable in practice. It can retrieve something similar, but cannot reliably tell you whether it is current, contradicted, superseded, partial, or merely adjacent, a gap the new agent memory systems are trying to close.
So:
- Embeddings give you associative recall.
- Versioning gives you update semantics.
- Temporal metadata gives you ordering.
- Source chunks give you grounding.
- Retrieval logic decides which layer to surface.
The most useful agentic systems will combine all of those pieces rather than trying to use just one of these to recreate 'memory'.
Agent memory is starting to look like state management
The deeper shift is that agent memory is starting to resemble real-world memory management more than just raw search.
A useful agent needs to find relevant information while possessing an up-to-date (or current) view of the world it is acting in.
Who owns this task right now?
Which design spec is the latest one?
What changed since yesterday?
Did this screenshot confirm the written note or contradict it?
Should this memory stay valuable, or should it expire after the task ends?
These are the kinds of questions those who work with AI frequently are now asking. New systems that answer them well will not just have better retrieval, as they will also have better update semantics, stronger temporal handling and stricter rules about what becomes memory at all.
The architecture is becoming clearer
The emerging pattern now looks something like this:
- embeddings handle broad semantic recall across large stores of material
- multimodal embeddings widen that recall across text, images, audio, video, and documents
- memory extraction turns raw material into smaller, higher-signal units
- temporal metadata tracks when something happened and when it was recorded
- relational versioning tracks what changed, what was extended, and what was inferred
- source grounding brings back the raw evidence when detail matters
- memory policy decides what should persist, what should update, and what should expire
What we are really seeing is a more systematic way to work around stateless models, which is probably how the most advanced and durable agent systems will be built in the coming few weeks (before a longer-term solution to memories for large language models is addressed).
The interesting change is not that models have magically become stateful. It is that the surrounding systems have become much better at compensating for statelessness.
Both Supermemory and Gemini Embedding 2 make the recall layer broader, while versioned and temporal memory systems make it more practical. Put together, they make agents look a little less like chat windows with long transcripts and a little more like systems that can carry state forward across changing conditions (perhaps in real-time, or close enough to it).
What we have right now isn't exactly the holy grail of frontier memory, but... it's also the one that seems most useful if you are actually building agents.
Try this prompt
Map the memory architecture around one AI workflow I use. Separate what the model can infer in the moment, what an external store needs to remember, how retrieval should work, how updates should be written back, and what should never be stored. Finish with a small implementation plan that distinguishes embeddings, episodic notes, user preferences, and task state.
Related on this site
- Agent Memory Architecture turns the argument in this essay into a visual model of extraction, versioning, multimodal recall, and source grounding.
- AI Workflow Notes collects the operating habits that matter once agents need reliable external state instead of longer chat history.
- AI Evaluation Checklist is the compact review layer I use when deciding whether an agent output is grounded enough to trust.