People talk about autonomous coding as if it's a single switch.
It's not.
What changes across the levels is the feedback loop around the work.
At the bottom, you're mostly removing friction: fewer permission prompts, better context hygiene, cleaner task boundaries. Higher up, you're changing the structure of the work itself: isolated subagents, stop hooks, retry loops, fixed evaluation metrics, and keep-or-revert branches.
Unattended runtime on its own isn't very interesting. Plenty of agents can keep typing. The question is whether they can tell if the last iteration made the work better, worse, or merely longer.
There's also a difference between what Anthropic officially ships and the operating patterns people have layered around it. They shouldn't be blurred together.
I also turned this piece into an interactive guide: Five Levels of Claude Code Autonomy.
Level 1: Remove permission friction
The first bottleneck is usually obvious.
If Claude has to ask for approval every time it edits a file, runs a test, or touches the shell, it stops being something you can leave alone for more than a few minutes.
Anthropic's permissions documentation now exposes several modes: default, acceptEdits, dontAsk, plan, and bypassPermissions. The current CLI also exposes both --dangerously-skip-permissions and --permission-mode bypassPermissions, plus --allow-dangerously-skip-permissions when you want bypass to be available without turning it on by default.
So yes, Level 1 is real. Kill the approval loop and Claude becomes much more usable.
But this is also the point where a lot of people confuse convenience with good operating practice.
Anthropic's own docs are explicit that bypassPermissions should only be used in isolated environments such as containers or VMs. Even then, writes to protected directories still prompt because accidentally corrupting .git, editor config, or Claude's own config is a very different category of mistake from changing normal project files.
What you're actually doing at this level is moving from constant manual approval to deliberate environmental control.
If the repo is trusted and the task is low-risk, acceptEdits or narrow allow rules may be enough. If you want unattended operation, then yes, full bypass is often the practical move, but only when the surrounding environment is disposable enough that mistakes are containable.
The shortcut is the flag.
The actual upgrade is the sandbox.
Practical guidance: treat bypass mode as an infrastructure decision, not a convenience setting. If you wouldn't hand the repo to a careless shell script, don't hand it to an unattended agent without isolation.
Level 2: Treat context as an operating budget
The second bottleneck is quieter.
Claude Code can now use 1 million token variants of Opus 4.6 and Sonnet 4.6, depending on the model and plan. That's a meaningful improvement for large codebases and long sessions.
It doesn't remove the need for context management.
Anthropic's docs still recommend clearing history between unrelated tasks with /clear, using /compact when a session is getting heavy, and watching token usage. The subagents documentation also notes that auto-compaction fires at about 95% capacity by default, with an override if you want it earlier.
The practical mistake at this level is to treat a larger context window as if it were durable memory.
It's still a working set.
Once a session is carrying old logs, abandoned plans, and stale assumptions, autonomy degrades quietly. The model may still look fluent. It just starts making weaker decisions because the session is full of residue from earlier work.
People who get more out of Claude Code tend to treat context like a budget rather than a container. They clear it between tasks. They compact before drift gets obvious. They move durable state into files, notes, scratchpads, or branches instead of pretending the live conversation should carry everything.
The 1 million token window helps.
It doesn't rescue sloppy session design.
Practical guidance: use one session per task when you can, clear aggressively between unrelated jobs, compact before the model starts drifting, and store durable state in files rather than chat history.
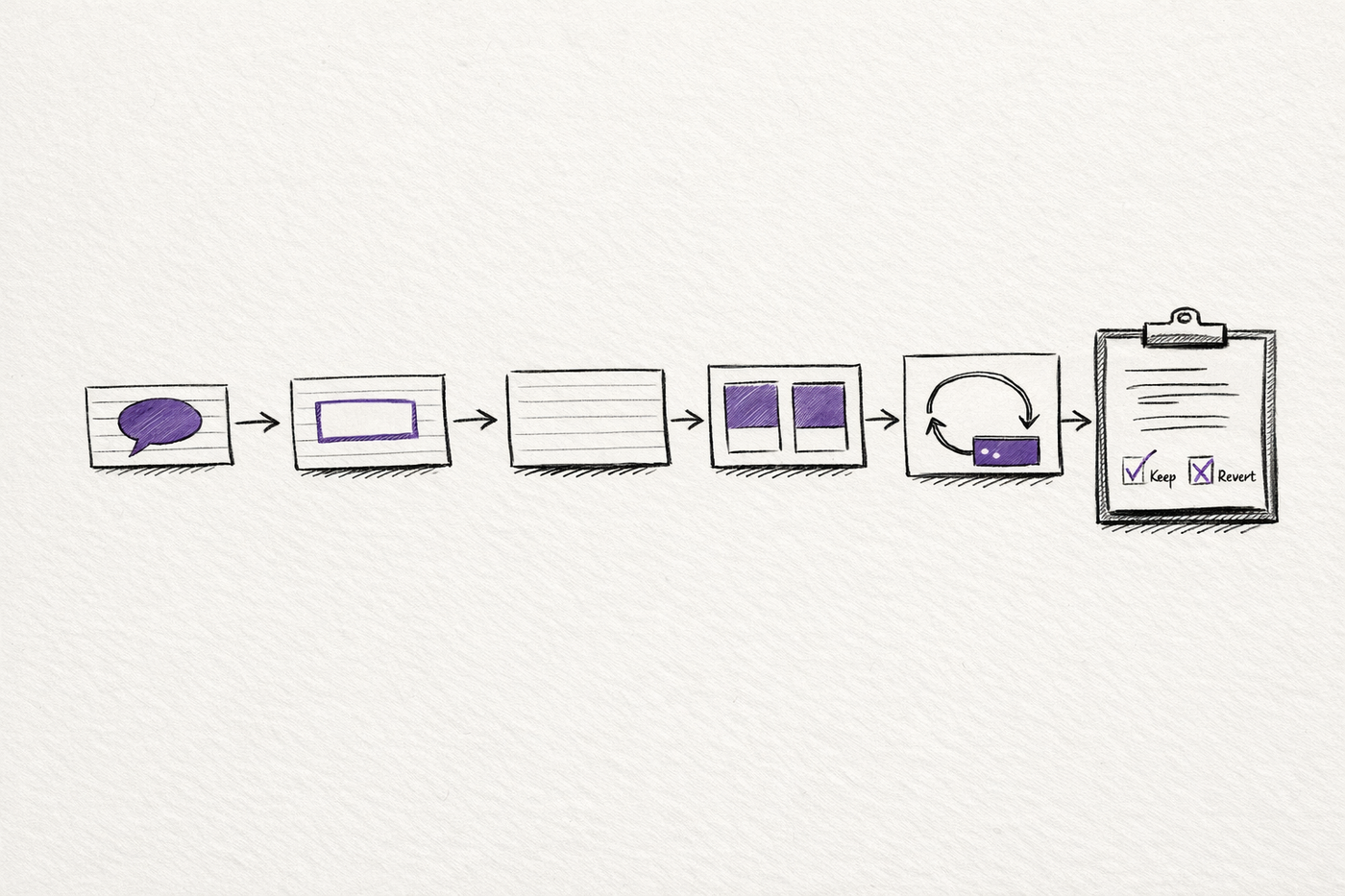
Level 3: Move work into separate contexts
This is where Claude Code starts becoming structurally more capable instead of merely less annoying.
Anthropic's subagents system is one of the clearest official answers to the familiar complaint that everything falls apart once too much work is packed into one conversation. Each subagent runs in its own context window with its own prompt, tool restrictions, model choice, and permission mode.
Not all context is equally valuable.
Test output, build logs, document fetches, repo exploration, and code review notes can all be useful. They're also all verbose. If every noisy step lands in the main conversation, the agent ends up spending a growing share of its budget carrying its own exhaust around.
Subagents fix part of that problem by keeping high-volume work local and returning a summary to the main thread. Anthropic explicitly recommends them for isolating tests, documentation fetches, and log processing.
This also changes how you structure autonomous work.
Instead of one general conversation that handles planning, code search, implementation, testing, debugging, and documentation all in the same place, you can break the work into roles. One agent explores. Another runs tests. Another reviews. Another handles a bounded implementation slice. The main conversation becomes more like an orchestrator than a single overstuffed worker.
There's still a limit. Anthropic's docs also point out that subagent results eventually return to the main conversation. If you run many subagents and each returns a dense summary, you can still burn through the main context. Subagents give you better boundaries, not infinite capacity.
Used well, though, they extend unattended runtime in a very practical way. They stop local noise from contaminating the main thread.
That's often enough to move from "useful for ten minutes" to "useful for a few hours".
Practical guidance: give subagents narrow roles and small return surfaces. Exploration, test runs, logs, docs, and bounded implementation slices are good fits. One giant all-purpose worker usually isn't.
Level 4: Turn stop into another iteration
Level 4 is where the community patterns get more interesting than the default product surface.
Anthropic's hooks system lets Claude Code run logic around session events, including stop events. Anthropic also now hosts a Ralph Wiggum plugin in the anthropics/claude-code repository that uses a Stop hook to intercept exit attempts and feed the same task back into the session until either a completion phrase appears or an iteration cap is hit.
The mechanism is simple.
Claude works, tries to stop, the hook blocks the exit, Claude sees the repo in its new state, and goes again. Files, git history, TODOs, and logs become the persistent memory between passes.
This is basically the community's while true trick moved closer to the product.
Geoffrey Huntley, whose Ralph write-up helped popularise the pattern, describes it very plainly: Ralph is a Bash loop. The RepoMirror field report from the YC Agents hackathon shows why the idea took off. Their team ran Claude Code headlessly in loops overnight, came back to more than a thousand commits across several projects, and got an almost functional TypeScript port of Browser Use out of the run.
That's enough to make the technique look magical if you only see the headline.
The more useful reading is narrower.
Ralph-style loops are persistence machinery. They're not verification machinery.
They help when a task benefits from repeated passes over the same working state. They don't, by themselves, tell the agent whether the work is now better. If the prompt is vague, if the success criteria are fuzzy, or if the checks are weak, the agent can spend hours producing motion without producing much value.
The Ralph plugin README keeps emphasising completion criteria, self-correction, iteration caps, and escape hatches. The loop is only as good as the test attached to it.
Use this level when "done" is crisp: tests passing, schema valid, benchmark achieved, docs generated, or a checklist fully closed.
Don't use it for vague product judgement, architecture drift, or tasks where the agent needs a human to decide what good looks like.
Practical guidance: attach Ralph-style loops to explicit checks, keep the prompt short, set a hard iteration cap, and tell the agent what to do if it gets stuck instead of letting it improvise forever.
Level 5: Stop rewarding activity and start rewarding measured improvement
This is the real jump.
Karpathy's autoresearch is a structured evaluation loop, not Claude Code left running for longer.
Karpathy's README describes the project as "AI agents running research on single-GPU nanochat training automatically". The repo keeps the editable surface small by asking the agent to work mainly on train.py, which is currently 630 lines long. Training runs for a fixed five-minute wall clock budget, the main metric is val_bpb, and the baseline program.md tells the agent to log each run, keep improvements, and revert regressions.
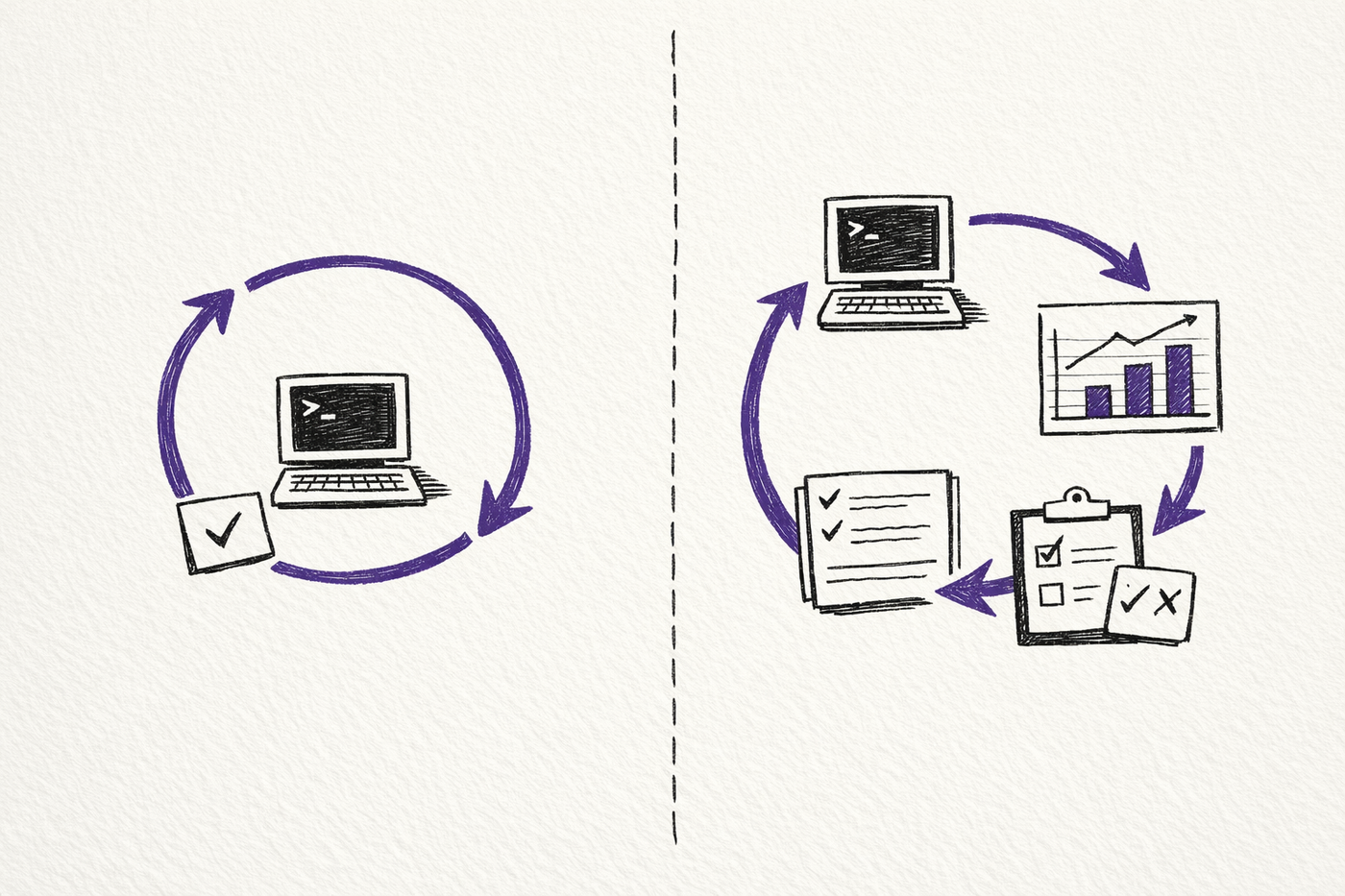
Ralph keeps going.
autoresearch measures, compares, and branches on outcome.
Karpathy's README says the fixed five-minute budget yields about 12 experiments per hour and roughly 100 overnight. That number is interesting, but what makes it work is the loop shape:
- a tightly bounded edit surface
- a fixed-cost experiment
- one trusted metric
- an append-only log of attempts
- a keep-or-revert decision after every run
Once you have that structure, the agent no longer needs to guess whether another iteration was productive. The system can tell.
This is also the level that generalises well beyond model training.
Replace val_bpb with whatever objective fits your domain: test pass rate, benchmark latency, bundle size, compiler success, bug reproduction rate, accessibility score, or conversion rate. The specific metric doesn't matter. Having one before the loop starts does.
Level 5 makes the most sense to me.
It's the first level where autonomy stops meaning "the agent kept working while I was away" and starts meaning "the system had a way to tell whether the work improved".
Practical guidance: start with one trusted metric, one small editable surface, and a clean keep-or-revert rule. If the agent can't tell a good iteration from a bad one, it's not autonomous. It's just unsupervised.
What Actually Changes Across the Levels
Most people get excited at Level 1 because it feels like the unlock.
It's not.
Removing permission prompts mostly removes operator friction.
The bigger gains come later:
- Level 2 keeps the session usable
- Level 3 creates better context boundaries
- Level 4 makes iteration persistent
- Level 5 makes iteration accountable
Claude Code gets more autonomous when it can inspect the consequences of its own work against something more reliable than momentum.
A bigger context window helps. Subagents help. Hooks help. Overnight loops help.
But "should I keep going?" isn't the interesting question. "Did that last iteration make things better?" is.
That's when autonomous coding stops being a party trick and starts being a way to work.
Try this prompt
Place my current Claude Code workflow on the five-level autonomy ladder. For each level, identify the missing operating habit, tool setting, test, or feedback loop that would let me move up one level without losing control. End with the smallest safe experiment I can run this week.
Related on this site
- Five Levels of Claude Code Autonomy is the interactive version of this framework if you want the shorter visual pass.
- Claude How-To Interactive Guide is the practical companion for Claude Code commands, memory, hooks, MCP, and subagent workflows.
- AI Evaluation Checklist is the simple review layer for the question this essay ends on: did the last iteration actually make the work better?