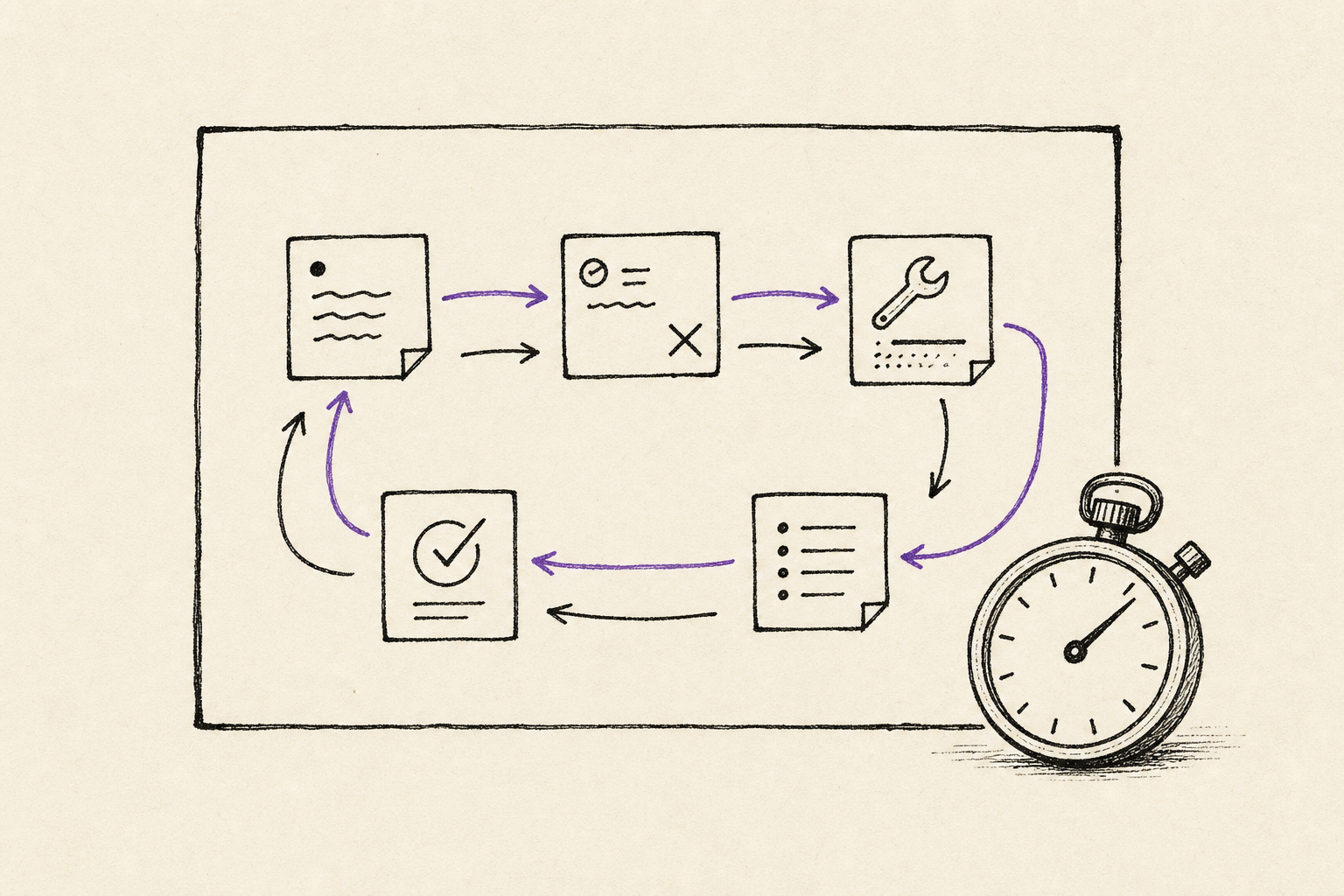
Fast inference is not interesting because it prints text quickly. It is interesting because it lets more supervised attempts happen before attention breaks.
The public signal is not a leaderboard crown. It is a coding-capable model served quickly enough to keep loops close.
The source pass changes the claim from "this model is fast" to "the client, queue, and streaming assumptions now need redesigning".
GLM 4.7 migration docs
Model ID, context, output, and reasoning-mode details.
Cerebras design guide
UI buffering, streaming, agent loops, and voice latency implications.
Kimi K2.6 enterprise trial
981 output tokens per second through a private Cerebras endpoint.
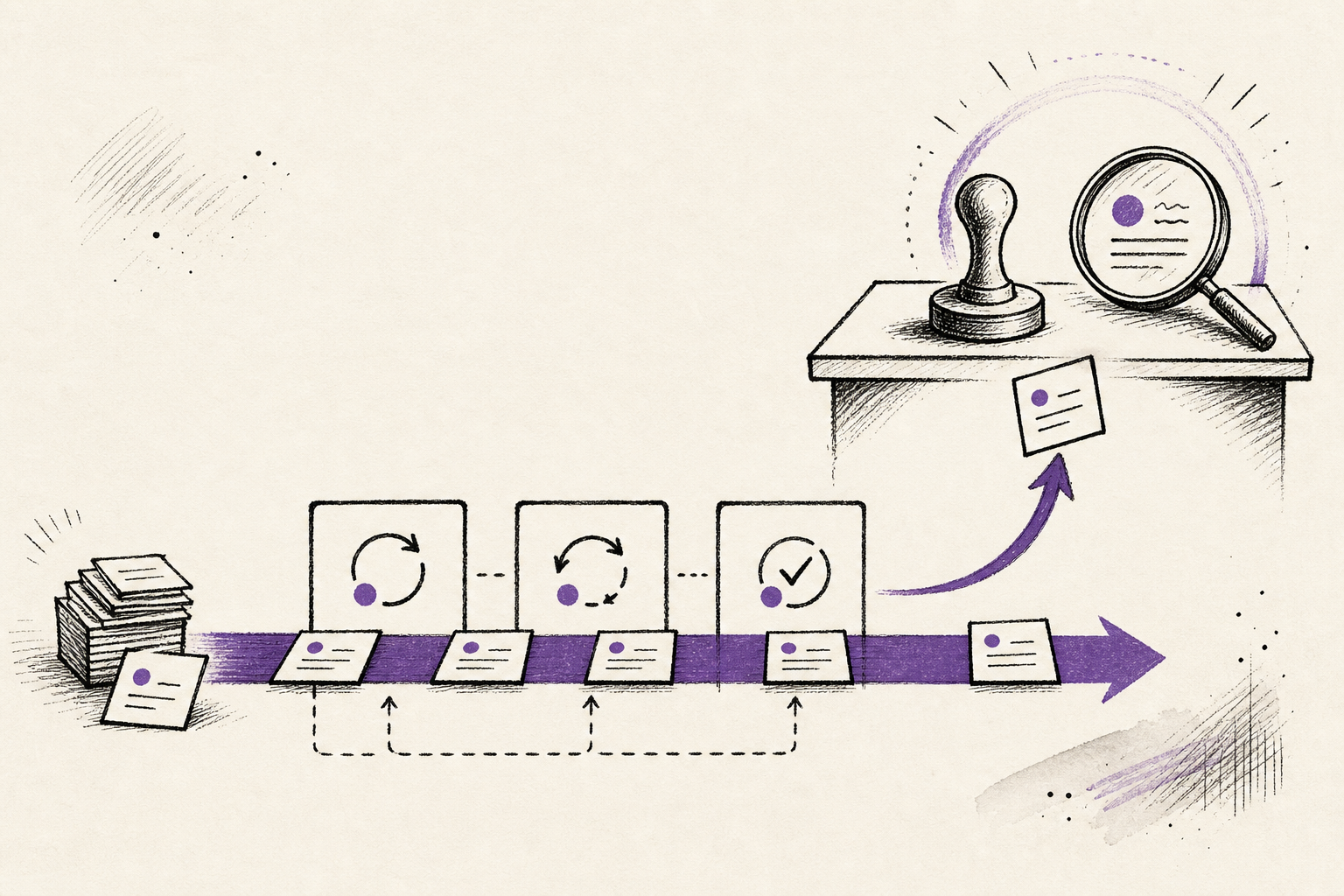
One fast answer is the small version. The larger move is several bounded passes staying close enough for the human to steer.
Draft the first version
Produce the rough answer while the human still has the intent in mind.
Run the critic
Look for the risky assumption, missing source, or likely failure point.
Repair or escalate
Fix the ordinary weakness quickly, or route the hard judgement to a ceiling model.